Transistors keep getting smaller and smaller, enabling computer chip designers to develop faster computer chips. But no matter how fast the chip gets, moving data from one part of the machine to another still takes time.
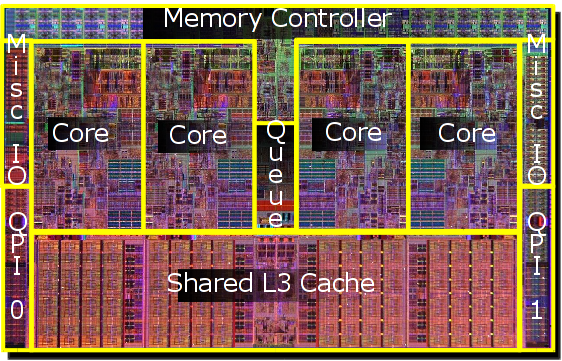
To date, chip designers have addressed this problem by placing small caches of local memory on or near the processor itself. Caches store the most frequently used data for easy access. But the days of a cache serving a single processor (or core) are over, making management of cache a nontrivial challenge. Additionally, cores typically have to share data, so the physical layout of the communication network connecting the cores needs to be considered, too.
Researchers at MIT and the University of Connecticut have now developed a set of new “rules” for cache management on multicore chips. Simulation results have shown that the rules significantly improve chip performance while simultaneously reducing the energy consumption. The researchers' first paper, presented at the IEEE International Symposium on Computer Architecture, reported gains (on average) of 15 percent in execution time and 25 percent energy savings.
So how are these caches typically managed, and what is this group doing differently?
Caches on multicore chips are arranged in a hierarchy, of sorts. Each core gets its own private cache, which can be divided into several levels based on how quickly it can be accessed. However there is also a shared cache, commonly referred to as the last-level cache (LLC), which all the cores are allowed to access.
Most chips use this level of organization and rely on what’s called the “spatiotemporal locality principle” to manage cache. Spatial locality means that if a piece of data is requested by a core, that same core will probably request other data stored near it in main memory. Temporal locality serves to say that if a core requests a piece of data, it is likely to need it again. Processors use these two patterns to try to keep the caches filled with the data that’s most likely to be needed next.
However this principle isn't flawless, and it comes up short when the data being stored exceeds the capacity of the core's private cache. In this case, the chip wastes a lot of time by trying to swap data around the cache hierarchy. This is the problem George Kurian, a graduate student in MIT's department of electrical engineering and computer science, is tackling.
Kurian worked with his advisor, Srini Devadas, at MIT and Omer Khan at the University of Connecticut, and their paper presents a hardware design that mitigates problems associated with the spatiotemporal locality principle. When the data being stored exceeds the capacity of the core's private cache, the chip splits up the data between private cache and the LLC. This ensures that the data is stored where it can be accessed more quickly than if it were in the main memory.
Another case addressed by the new work occurs when two cores are working on the same data and are constantly synchronizing their cached version. Here, the technique eliminates the synchronization operation and simply stores the shared data at a single location in the LLC. Then the cores take turns accessing the data, rather than clogging the on-chip network with synchronization operations.
The new paper examines another case, where two cores are working on the same data but not synchronizing it frequently. Typically, the LLC is treated as a single memory bank, and the data is distributed across the chip in discrete chunks. The team has developed a second circuit to treat this chunk as extensions of each core’s private cache. This allows each core to have its own copy of the data in the LLC, allowing much faster access to data.
The nice thing about this work is that it impacts a number of aspects of a processor’s function. By making the caching algorithms a bit smarter, the researchers could both speed execution of code, while cutting down on the number of commands that needed to be executed simply to manage memory. With fewer commands being executed, energy use necessarily dropped.
reader comments
64