

Javac是什么
通常,一个java文件会通过编译器编译成字节码文件.class,再又java虚拟机JVM翻译成计算机可执行的文件。
我们所知道的java语言有它自己的语法规范,同样的JVM也有它的语法规范,如何让java的语法规则去适应语法解析规则,这就是javac的作用,简而言之,javac的作用就是将java源代码转化成class字节码文件。
Javac编译器的基本结构
编译步骤
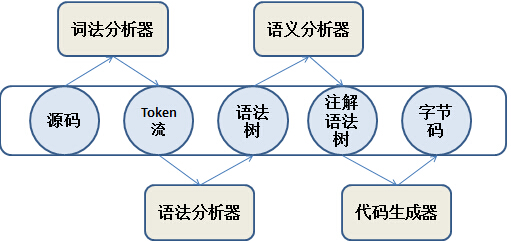
1. 词法分析器:
1.1作用:
将源码转化为Token流
1.2流程
读取源代码,从源文件的一个字符开始,按照java语法规范依次找出package,import,类定义,属性,方法定义等,最后构建出一个抽象语法树
1.3举例
package compile;
/**
* 词法解析器
*/
public class Cifa{
int a;
int c = a + 1;
}
转化为Token流:
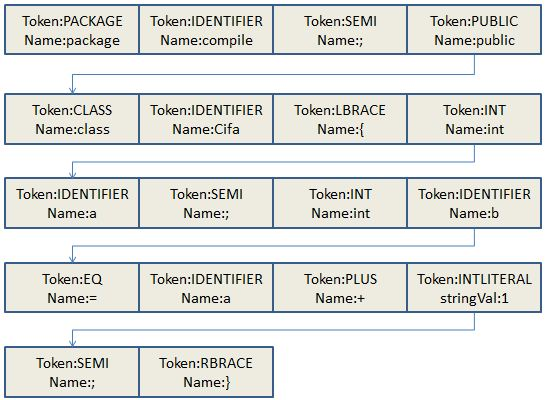
1.4源码分析
- com.sun.tools.javac.parser.JavacParser 规定哪些词符合Java语言规范,具体读取和归类不同词法的操作由scanner完成
- com.sun.tools.javac.parser.Scanner 负责逐个读取源代码的单个字符,然后解析符合Java语言规范的Token序列,调用一次nextToken()都构造一个Token
- com.sun.tools.javac.parser.Tokens$TokenKind 里面包含了所有token的类型,譬如BOOLEAN,BREAK,BYTE,CASE。
- com.sun.tools.javac.util.Names 用来存储和表示解析后的词法,每个字符集合都会是一个Name对象,所有的对象都存储在Name.Table这个内部类中。
- com.sun.tools.javac.parser.KeyWords 负责将字符集合对应到token集合中,如,package zxy.demo.com; Token.PACKAGE = package, Token.IDENTIFIER = zxy.demo.com,(这部分又分为读取第一个token,为zxy,判断下一个token是否为“.”,是的话接着读取下一个Token.IDENTIFIER类型的token,反复直至下一个token不是”.”,也就是说下一个不是Token.IDENIFIER类型的token,Token.SEMI = ;即这个TIDENTIFIER类型的token的Name读完),KeyWords类负责此任务。
1.5问题
Javac是如何分辨这一个个Token呢?例如它时如何直到package是关键词而不是自定义变量呢?
Javac在进行此法分析时会由JavacParser根据Java语言规范来控制什么顺序,地方会出现什么Token,例如package就只能在文件的最开头出现
Javac怎样确定哪些字符组合在一起就是一个Token呢?它如何从一串字符流中划分出Token来?
对于关键字,主要由关键字的语法规则,例如package就是若一个字符串package是连续的,那么他就是关键字
对于自定义变量名称,自定义名称之间用空格隔开,每个语法表达式用分号结束
举例:
int a = 1 + 2;
从package开始
.....
int 就是通过语法关键字判定的TOKEN:INT
int a之间通过空格隔开
a 就是自定义的变量被判定为TOKEN:IDENTIFIER
a =之间通过空格隔开(这时有的小伙伴就会说了,int a=b+c;这句话也不报错啊,对的,大多数时候,这种不用空格分开确实能够编译,这是因为java指出声明变量的时候必须以字母、下划线或者美元符开头,当JavacParser读完a去读=的时候就直到这个=不属于变量了)将=判定为TOKEN:EQ
1被判定为TOKEN:INTLITERAL
.....
将;识别为TOKEN:SEMI
.....
最后读取到类结束,也就是}被判定为TOKEN:RBRACE
2.语法分析器:
刚才,词法解析器已经将Java源文件解析成了Token流。
现在,语法解析器就要将Token流组建成更加结构化的语法树。也就是将这些Token流中的单词装成一句话,完整的语句。
2.1作用
将进行词法分析后形成的Token流中的一个个Token组成一句句话,检查这一句句话是不是符合Java语言规范。
2.2语法分析三部分
- package
- import
- 类(包含class、interface、enum),一下提到的类泛指这三类,并不单单是指class
2.3所用类库
- com.sun.tools.javac.tree.TreeMaker 所有语法节点都是由它生成的,根据Name对象构建一个语法节点
- com.sun.tools.javac.tree.JCTree$JCIf 所有的节点都会继承jctree和实现**tree,譬如 JCIf extends JCTree.JCStatement implements IfTree
- com.sun.tools.javac.tree.JCTree的三个属性
-
Tree tag:每个语法节点都会以整数的形式表示,下一个节点在上一个节点上加1; -
pos:也是一个整数,它存储的是这个语法节点在源代码中的起始位置,一个文件的位置是0,而-1表示不存在 -
type:它代表的是这个节点是什么java类型,如int,float,还是string等
-
2.4 举例
package compile;
/**
* 语法
*/
public class Yufa {
int a;
private int c = a + 1;
//getter
public int getC() {
return c;
}
//setter
public void setC(int c) {
this.c = c;
}
}
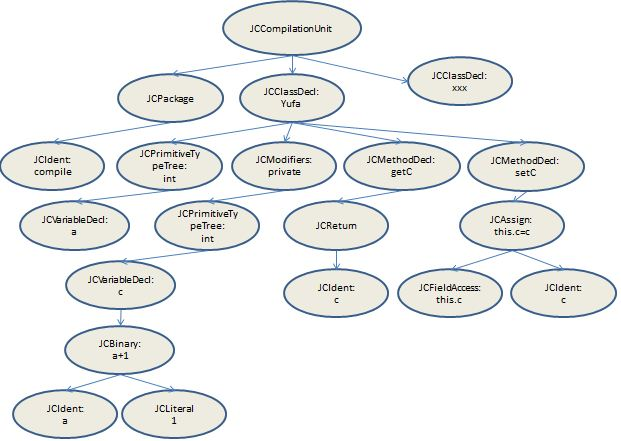
- 每一个包package下的所有类都会放在一个JCCompilationUnit节点下,在该节点下包含:package语法树(作为pid)、各个类的语法树
- 每一个从JCClassDecl发出的分支都是一个完整的代码块,上述是四个分支,对应我们代码中的两行属性操作语句和两个方法块代码块,这样其实就完成了语法分析器的作用:将一个个Token单词组成了一句句话(或者说成一句句代码块)
- 在上述的语法树部分,对于属性操作部分是完整的,但是对于两个方法块,省略了一些语法节点,例如:方法修饰符public、方法返回类型、方法参数。
注1:若类中有import关键字则途中还有import的语法节点
注2:所有语法节点的生成都是在TreeMaker类中完成的
3.语义分析器
3.1作用
将语法树转化为注解语法树,即在这颗语法树上做一些处理
3.2步骤
-
给类添加默认构造函数(由com.sun.tools.javac.comp.Enter类完成)
-
处理注解(由com.sun.tools.javac.processing.JavacProcessingEnvironment类完成)
-
检查语义的合法性并进行逻辑判断(由com.sun.tools.javac.comp.Attr完成)
- 变量的类型是否匹配
- 变量在使用前是否初始化
- 能够推导出泛型方法的参数类型
- 字符串常量合并
-
数据流分析(由com.sun.tools.javac.comp.Flow类完成)
- 检验变量是否被正确赋值(eg.有返回值的方法必须确定有返回值)
- 保证final变量不会被重复修饰
- 确定方法的返回值类型
- 所有的检查型异常是否抛出或捕获
- 所有的语句都要被执行到(return后边的语句就不会被执行到,除了finally块儿)
-
对语法树进行语义分析(由com.sun.tools.javac.comp.Flow执行)
- 去掉无用的代码,如只有永假的if代码块
- 变量的自动转换,如将int自动包装为Integer类型
- 去除语法糖,将foreach的形式转化为更简单的for循环
最终,生成了注解语法树
3.3所用类库
- com.sun.tools.javac.comp.Check,它用来辅助Attr类检查语法树中变量类型是否正确,如方法返回值是否和接收的引用值类型匹配
- com.sun.tools.javac.comp.Resolve,用来检查变量,方法或者类的访问是否合法,变量是否是静态变量
- com.sun.tools.javac.comp.ConstFold,将一个字符串常量中的多个字符合并成一个字符串
- com.sun.tools.javac.comp.Infer,帮助推导泛型方法的参数类型
3.4举例
变量自动转化
public class Yuyi{
public static void main(String agrs[]){
Integer i = 1;
Long l = i + 2L;
System.out.println(l);
}
}
//经过自动转换后
public class Yuyi{
public Yuyi(){
super();
}
public static void main(String agrs[]){
Integer i = Integer.valueOf(1);
Long l = Long.valueOf(i.intValue() + 2L);
System.out.println(l);
}
}
解除语法糖
public class Yuyi{
public static void main(String agrs[]){
int[] array = {1,2,3};
for (int i : array){
System.out.println(i);
}
}
}
//解除语法糖后
public class Yuyi{
public Yuyi(){
super();
}
public static void main(String agrs[]){
int[] arrays = {1,2,3};
for (int[] arr$ = array,len$=arr$.length,i$=0; i$<len$; ++i$){
int i = arr$[i$];
{
System.out.println(i);
}
}
}
}
内部类解析
public class Yuyi{
public static void main(String agrs[]){
Inner inner = new Inner();
inner.print();
}
class Inner{
public void print(){
System.out.println("Yuyi$Inner.print");
}
}
}
//转化后的代码如下
public class Yuyi{
public Yuyi(){
super();
}
public static void main(String agrs[]){
Yuyi$Inner inner = new Yuyi$Inner(this);
inner.print();
}
{
}
}
class Yuyi$Inner{
/*synthetic*/ final Yuyi this$0;
Yuyi$Inner(/*synthetic*/final Yuyi this$0){
this.this$0 = this$0;
super();
}
public void print(){
System.out.println("Yuyi$Inner.print");
}
}
4.代码生成器
4.1作用
生成语法树后,接下来Javac会调用com.sun.tools.javac.jvm.Gen类遍历语法树,生成Java字节码
4.2步骤
- 将java方法中代码块转化为符合JVM语法的命令形式,JVM的操作都是基于栈的,所有的操作都必须经过出栈和进栈来完成
- 按照JVM的文件组织格式将字节码输出到以class为拓展名的文件中
4.3所用类库
- com.sun.tools.javac.jvm.Gen类,用来遍历语法树,生成最终Java字节码
- com.sun.tools.javac.jvm.Items,辅助gen,这个类表示任何可寻址的操作项,这些操作项都可以作为一个单位出现在操作栈上
- com.sun.tools.javac.jvm.Code,辅助gen,存储生成的字节码,并提供一些能够映射操作码的方法
参考书籍:《深入分析Java Web》
