Collaborative Filtering at Spotify
281 likes93,393 views

From the NYC Machine Learning meetup on Jan 17, 2013: http://www.meetup.com/NYC-Machine-Learning/events/97871782/ Video is available here: http://vimeo.com/57900625


















































































More Related Content
What's hot (20)
Similar to Collaborative Filtering at Spotify (20)


















Recently uploaded (20)




















Collaborative Filtering at Spotify
- 1. Music recommendations at Spotify Erik Bernhardsson erikbern@spotify.com
- 2. Recommendation stuff at Spotify
- 3. Collaborative filtering
- 4. Collaborative filtering Idea: - If two movies x, y get similar ratings then they are probably similar - If a lot of users all listen to tracks x, y, z, then those tracks are probably similar
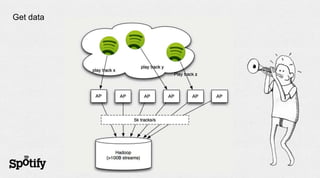
- 5. Get data
- 6. … lots of data
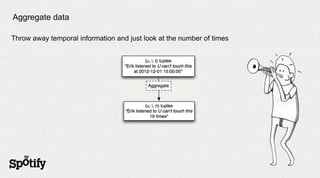
- 7. Aggregate data Throw away temporal information and just look at the number of times
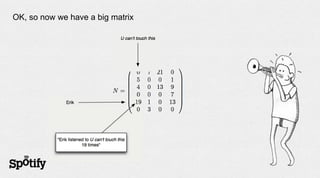
- 8. OK, so now we have a big matrix
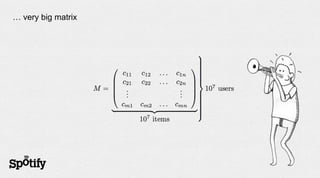
- 9. … very big matrix
- 10. Supervised collaborative filtering is pretty much matrix completion
- 11. Supervised learning: Matrix completion
- 12. Supervised: evaluating rec quality
- 13. Unsupervised learning - Trying to estimate the density - i.e. predict probability of future events
- 14. Try to predict the future given the past
- 15. How can we find similar items
- 16. We can calculate correlation coefficient as an item similarity - Use something like Pearson, Jaccard, …
- 17. Amazon did this for “customers who bought this also bought” - US patent 7113917
- 18. Parallelization is hard though
- 19. Parallelization is hard though
- 20. Can speed this up using various LSH tricks - Twitter: Dimension Independent Similarity Computation (DISCO)
- 21. Are there other approaches?
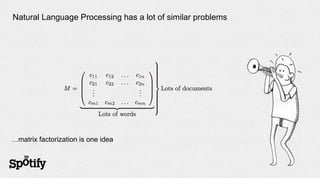
- 22. Natural Language Processing has a lot of similar problems …matrix factorization is one idea
- 23. Matrix factorization
- 24. Matrix factorization - Want to get user vectors and item vectors - Assume f latent factors (dimensions) for each user/item
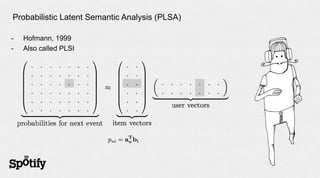
- 25. Probabilistic Latent Semantic Analysis (PLSA) - Hofmann, 1999 - Also called PLSI
- 26. PLSA, cont. + a bunch of constraints:
- 27. PLSA, cont. Optimization problem: maximize log-likelihood
- 28. PLSA, cont.
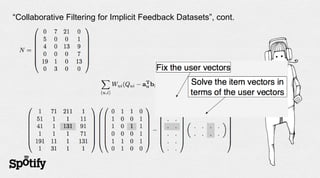
- 33. “Collaborative Filtering for Implicit Feedback Datasets” - Hu, Koren, Volinsky (2008)
- 34. “Collaborative Filtering for Implicit Feedback Datasets”, cont.
- 35. “Collaborative Filtering for Implicit Feedback Datasets”, cont.
- 36. “Collaborative Filtering for Implicit Feedback Datasets”, cont.
- 37. “Collaborative Filtering for Implicit Feedback Datasets”, cont.
- 38. Here is another method we use
- 39. What happens each iteration - Assign all latent vectors small random values - Perform gradient ascent to optimize log-likelihood
- 40. What happens each iteration - Assign all latent vectors small random values - Perform gradient ascent to optimize log-likelihood
- 41. What happens each iteration - Assign all latent vectors small random values - Perform gradient ascent to optimize log-likelihood
- 42. Calculate derivative and do gradient ascent - Assign all latent vectors small random values - Perform gradient ascent to optimize log-likelihood
- 43. 2D iteration example
- 44. Vectors are pretty nice because things are now super fast - User-item score is a dot product: - Item-item similarity score is a cosine similarity: - Both cases have trivial complexity in the number of factors f:
- 45. Example: item similarity as a cosine of vectors
- 46. Two dimensional example for tracks
- 47. We can rank all tracks by the user’s vector
- 48. So how do we implement this?
- 49. One iteration of a matrix factorization algorithm “Google News personalization: scalable online collaborative filtering”
- 51. So now we solved the problem of recommendations right?
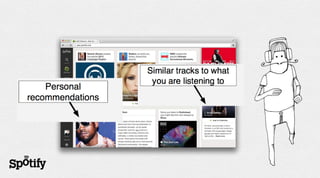
- 52. Actually what we really want is to apply it to other domains
- 53. Radio - Artist radio: find related tracks - Optimize ensemble model based on skip/thumbs data
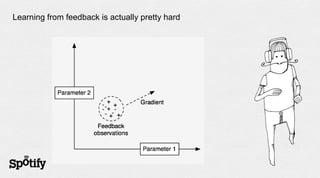
- 54. Learning from feedback is actually pretty hard
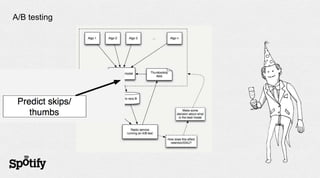
- 55. A/B testing
- 56. A/B testing
- 57. A/B testing
- 58. A/B testing
- 59. More applications!!!
- 62. Last but not least: we’re hiring!
- 63. Thank you