Rainbird: Realtime Analytics at Twitter (Strata 2011)
Download as KEY, PDF257 likes77,629 views

Introducing Rainbird, Twitter's high volume distributed counting service for realtime analytics, built on Cassandra. This presentation looks at the motivation, design, and uses of Rainbird across Twitter.

























![Hierarchical Aggregation
‣ Say we’re counting Promoted Tweet impressions
‣ category = pti
‣ keys = [advertiser_id, campaign_id, tweet_id]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [advertiser_id, campaign_id, tweet_id]
‣ [advertiser_id, campaign_id]
‣ [advertiser_id]
‣ Means fast queries over each level of hierarchy
‣ Configurable in rainbird.conf, or dynamically via ZK](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-33-320.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music]
‣ [com, amazon]
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-34-320.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] full URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-35-320.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] any music.amazon.com URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-36-320.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] any amazon.com URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-37-320.jpg)
![Hierarchical Aggregation
‣ Another example: tracking URL shortener tweets/clicks
‣ full URL = http://music.amazon.com/some_really_long_path
‣ keys = [com, amazon, music, full URL]
‣ count = 1
‣ Rainbird automatically increments the count for
‣ [com, amazon, music, full URL]
‣ [com, amazon, music] How many people tweeted
‣ [com, amazon] any .com URL?
‣ [com]
‣ Means we can count clicks on full URLs
‣ And automatically aggregate over domains and subdomains!](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-38-320.jpg)





![Production Uses
‣ Internal Monitoring and Alerting
‣ We require operational reporting on all internal services
‣ Needs to be real-time, but also want longer-term
aggregates
‣ Hierarchical, too: [stat, datacenter, service, machine]](https://image.slidesharecdn.com/realtimeanalyticsattwitter-strata2011-110204123031-phpapp02/85/Rainbird-Realtime-Analytics-at-Twitter-Strata-2011-48-320.jpg)










































More Related Content
What's hot (20)
Viewers also liked (19)

















Similar to Rainbird: Realtime Analytics at Twitter (Strata 2011) (20)

![[CB16] 80時間でWebを一周:クロムミウムオートメーションによるスケーラブルなフィンガープリント by Isaac Dawson](https://cdn.slidesharecdn.com/ss_thumbnails/cb16dawsonja-161109051202-thumbnail.jpg?width=560&fit=bounds)


















Rainbird: Realtime Analytics at Twitter (Strata 2011)
- 1. Rainbird: Real-time Analytics @Twitter Kevin Weil -- @kevinweil Product Lead for Revenue, Twitter TM
- 2. Agenda ‣ Why Real-time Analytics? ‣ Rainbird and Cassandra ‣ Production Uses at Twitter ‣ Open Source
- 3. My Background ‣ Mathematics and Physics at Harvard, Physics at Stanford ‣ Tropos Networks (city-wide wireless): mesh routing algorithms, GBs of data ‣ Cooliris (web media): Hadoop and Pig for analytics, TBs of data ‣ Twitter: Hadoop, Pig, HBase, Cassandra, data viz, social graph analysis, soon to be PBs of data
- 4. My Background ‣ Mathematics and Physics at Harvard, Physics at Stanford ‣ Tropos Networks (city-wide wireless): mesh routing algorithms, GBs of data ‣ Cooliris (web media): Hadoop and Pig for analytics, TBs of data ‣ Twitter: Hadoop, Pig, HBase, Cassandra, data viz, social graph analysis, soon to be PBs of data Now revenue products!
- 5. Agenda ‣ Why Real-time Analytics? ‣ Rainbird and Cassandra ‣ Production Uses at Twitter ‣ Open Source
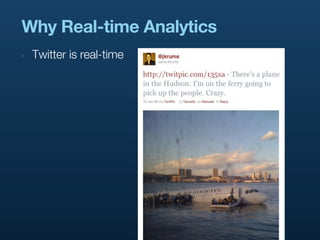
- 6. Why Real-time Analytics ‣ Twitter is real-time
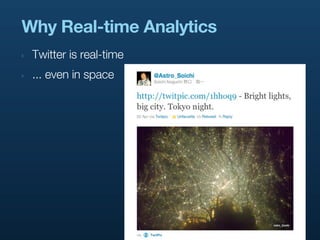
- 7. Why Real-time Analytics ‣ Twitter is real-time ‣ ... even in space
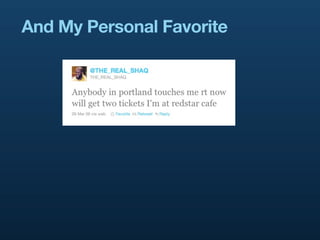
- 8. And My Personal Favorite
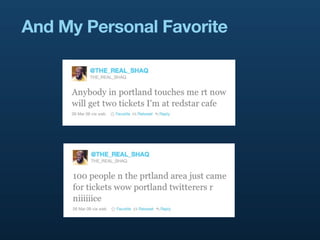
- 9. And My Personal Favorite
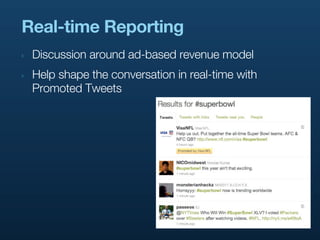
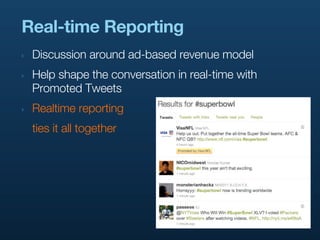
- 10. Real-time Reporting ‣ Discussion around ad-based revenue model ‣ Help shape the conversation in real-time with Promoted Tweets
- 11. Real-time Reporting ‣ Discussion around ad-based revenue model ‣ Help shape the conversation in real-time with Promoted Tweets ‣ Realtime reporting ties it all together
- 12. Agenda ‣ Why Real-time Analytics? ‣ Rainbird and Cassandra ‣ Production Uses at Twitter ‣ Open Source
- 13. Requirements ‣ Extremely high write volume ‣ Needs to scale to 100,000s of WPS
- 14. Requirements ‣ Extremely high write volume ‣ Needs to scale to 100,000s of WPS ‣ High read volume ‣ Needs to scale to 10,000s of RPS
- 15. Requirements ‣ Extremely high write volume ‣ Needs to scale to 100,000s of WPS ‣ High read volume ‣ Needs to scale to 10,000s of RPS ‣ Horizontally scalable (reads, storage, etc) ‣ Needs to scale to 100+ TB
- 16. Requirements ‣ Extremely high write volume ‣ Needs to scale to 100,000s of WPS ‣ High read volume ‣ Needs to scale to 10,000s of RPS ‣ Horizontally scalable (reads, storage, etc) ‣ Needs to scale to 100+ TB ‣ Low latency ‣ Most reads <100 ms (esp. recent data)
- 17. Cassandra ‣ Pro: In-house expertise ‣ Pro: Open source Apache project ‣ Pro: Writes are extremely fast ‣ Pro: Horizontally scalable, low latency ‣ Pro: Other startup adoption (Digg, SimpleGeo)
- 18. Cassandra ‣ Pro: In-house expertise ‣ Pro: Open source Apache project ‣ Pro: Writes are extremely fast ‣ Pro: Horizontally scalable, low latency ‣ Pro: Other startup adoption (Digg, SimpleGeo) ‣ Con: It was really young (0.3a)
- 19. Cassandra ‣ Pro: Some dudes at Digg had already started working on distributed atomic counters in Cassandra
- 20. Cassandra ‣ Pro: Some dudes at Digg had already started working on distributed atomic counters in Cassandra ‣ Say hi to @kelvin
- 21. Cassandra ‣ Pro: Some dudes at Digg had already started working on distributed atomic counters in Cassandra ‣ Say hi to @kelvin ‣ And @lenn0x
- 22. Cassandra ‣ Pro: Some dudes at Digg had already started working on distributed atomic counters in Cassandra ‣ Say hi to @kelvin ‣ And @lenn0x ‣ A dude from Sweden began helping: @skr
- 23. Cassandra ‣ Pro: Some dudes at Digg had already started working on distributed atomic counters in Cassandra ‣ Say hi to @kelvin ‣ And @lenn0x ‣ A dude from Sweden began helping: @skr ‣ Now all at Twitter :)
- 24. Rainbird ‣ It counts things. Really quickly. ‣ Layers on top of the distributed counters patch, CASSANDRA-1072
- 25. Rainbird ‣ It counts things. Really quickly. ‣ Layers on top of the distributed counters patch, CASSANDRA-1072 ‣ Relies on Zookeeper, Cassandra, Scribe, Thrift ‣ Written in Scala
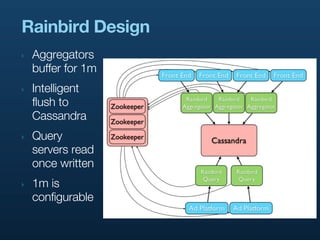
- 26. Rainbird Design ‣ Aggregators buffer for 1m ‣ Intelligent flush to Cassandra ‣ Query servers read once written ‣ 1m is configurable
- 27. Rainbird Data Structures struct Event { 1: i32 timestamp, 2: string category, 3: list<string> key, 4: i64 value, 5: optional set<Property> properties, 6: optional map<Property, i64> propertiesWithCounts }
- 28. Rainbird Data Structures struct Event { Unix timestamp of event 1: i32 timestamp, 2: string category, 3: list<string> key, 4: i64 value, 5: optional set<Property> properties, 6: optional map<Property, i64> propertiesWithCounts }
- 29. Rainbird Data Structures struct Event { Stat category name 1: i32 timestamp, 2: string category, 3: list<string> key, 4: i64 value, 5: optional set<Property> properties, 6: optional map<Property, i64> propertiesWithCounts }
- 30. Rainbird Data Structures struct Event { Stat keys (hierarchical) 1: i32 timestamp, 2: string category, 3: list<string> key, 4: i64 value, 5: optional set<Property> properties, 6: optional map<Property, i64> propertiesWithCounts }
- 31. Rainbird Data Structures struct Event { Actual count (diff) 1: i32 timestamp, 2: string category, 3: list<string> key, 4: i64 value, 5: optional set<Property> properties, 6: optional map<Property, i64> propertiesWithCounts }
- 32. Rainbird Data Structures struct Event { More later 1: i32 timestamp, 2: string category, 3: list<string> key, 4: i64 value, 5: optional set<Property> properties, 6: optional map<Property, i64> propertiesWithCounts }
- 33. Hierarchical Aggregation ‣ Say we’re counting Promoted Tweet impressions ‣ category = pti ‣ keys = [advertiser_id, campaign_id, tweet_id] ‣ count = 1 ‣ Rainbird automatically increments the count for ‣ [advertiser_id, campaign_id, tweet_id] ‣ [advertiser_id, campaign_id] ‣ [advertiser_id] ‣ Means fast queries over each level of hierarchy ‣ Configurable in rainbird.conf, or dynamically via ZK
- 34. Hierarchical Aggregation ‣ Another example: tracking URL shortener tweets/clicks ‣ full URL = http://music.amazon.com/some_really_long_path ‣ keys = [com, amazon, music, full URL] ‣ count = 1 ‣ Rainbird automatically increments the count for ‣ [com, amazon, music, full URL] ‣ [com, amazon, music] ‣ [com, amazon] ‣ [com] ‣ Means we can count clicks on full URLs ‣ And automatically aggregate over domains and subdomains!
- 35. Hierarchical Aggregation ‣ Another example: tracking URL shortener tweets/clicks ‣ full URL = http://music.amazon.com/some_really_long_path ‣ keys = [com, amazon, music, full URL] ‣ count = 1 ‣ Rainbird automatically increments the count for ‣ [com, amazon, music, full URL] ‣ [com, amazon, music] How many people tweeted ‣ [com, amazon] full URL? ‣ [com] ‣ Means we can count clicks on full URLs ‣ And automatically aggregate over domains and subdomains!
- 36. Hierarchical Aggregation ‣ Another example: tracking URL shortener tweets/clicks ‣ full URL = http://music.amazon.com/some_really_long_path ‣ keys = [com, amazon, music, full URL] ‣ count = 1 ‣ Rainbird automatically increments the count for ‣ [com, amazon, music, full URL] ‣ [com, amazon, music] How many people tweeted ‣ [com, amazon] any music.amazon.com URL? ‣ [com] ‣ Means we can count clicks on full URLs ‣ And automatically aggregate over domains and subdomains!
- 37. Hierarchical Aggregation ‣ Another example: tracking URL shortener tweets/clicks ‣ full URL = http://music.amazon.com/some_really_long_path ‣ keys = [com, amazon, music, full URL] ‣ count = 1 ‣ Rainbird automatically increments the count for ‣ [com, amazon, music, full URL] ‣ [com, amazon, music] How many people tweeted ‣ [com, amazon] any amazon.com URL? ‣ [com] ‣ Means we can count clicks on full URLs ‣ And automatically aggregate over domains and subdomains!
- 38. Hierarchical Aggregation ‣ Another example: tracking URL shortener tweets/clicks ‣ full URL = http://music.amazon.com/some_really_long_path ‣ keys = [com, amazon, music, full URL] ‣ count = 1 ‣ Rainbird automatically increments the count for ‣ [com, amazon, music, full URL] ‣ [com, amazon, music] How many people tweeted ‣ [com, amazon] any .com URL? ‣ [com] ‣ Means we can count clicks on full URLs ‣ And automatically aggregate over domains and subdomains!
- 39. Temporal Aggregation ‣ Rainbird also does (configurable) temporal aggregation ‣ Each count is kept minutely, but also denormalized hourly, daily, and all time ‣ Gives us quick counts at varying granularities with no large scans at read time ‣ Trading storage for latency
- 40. Multiple Formulas ‣ So far we have talked about sums ‣ Could also store counts (1 for each event) ‣ ... which gives us a mean ‣ And sums of squares (count * count for each event) ‣ ... which gives us a standard deviation ‣ And min/max as well ‣ Configure this per-category in rainbird.conf
- 41. Rainbird ‣ Write 100,000s of events per second, each with hierarchical structure ‣ Query with minutely granularity over any level of the hierarchy, get back a time series ‣ Or query all time values ‣ Or query all time means, standard deviations ‣ Latency < 100ms
- 42. Agenda ‣ Why Real-time Analytics? ‣ Rainbird and Cassandra ‣ Production Uses at Twitter ‣ Open Source
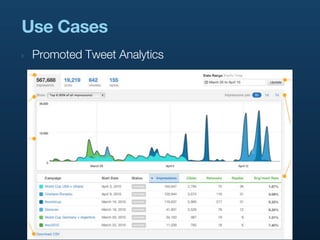
- 43. Production Uses ‣ It turns out we need to count things all the time ‣ As soon as we had this service, we started finding all sorts of use cases for it ‣ Promoted Products ‣ Tweeted URLs, by domain/subdomain ‣ Per-user Tweet interactions (fav, RT, follow) ‣ Arbitrary terms in Tweets ‣ Clicks on t.co URLs
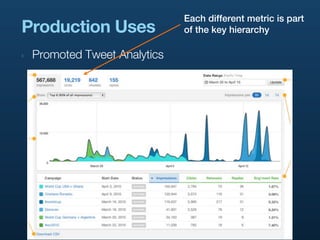
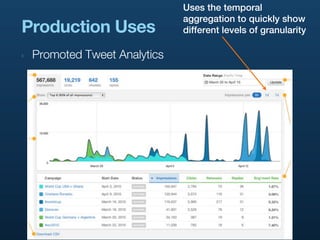
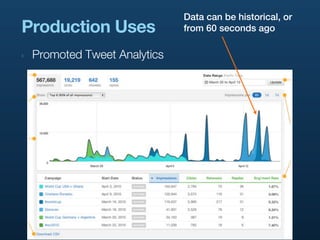
- 44. Use Cases ‣ Promoted Tweet Analytics
- 45. Each different metric is part Production Uses of the key hierarchy ‣ Promoted Tweet Analytics
- 46. Uses the temporal aggregation to quickly show Production Uses different levels of granularity ‣ Promoted Tweet Analytics
- 47. Data can be historical, or Production Uses from 60 seconds ago ‣ Promoted Tweet Analytics
- 48. Production Uses ‣ Internal Monitoring and Alerting ‣ We require operational reporting on all internal services ‣ Needs to be real-time, but also want longer-term aggregates ‣ Hierarchical, too: [stat, datacenter, service, machine]
- 49. Production Uses ‣ Tweet Button Counts ‣ Tweet Button counts are requested many many times each day from across the web ‣ Uses the all time field
- 50. Agenda ‣ Why Real-time Analytics? ‣ Rainbird and Cassandra ‣ Production Uses at Twitter ‣ Open Source
- 51. Open Source? ‣ Yes!
- 52. Open Source? ‣ Yes! ... but not yet
- 53. Open Source? ‣ Yes! ... but not yet ‣ Relies on unreleased version of Cassandra
- 54. Open Source? ‣ Yes! ... but not yet ‣ Relies on unreleased version of Cassandra ‣ ... but the counters patch is committed in trunk (0.8)
- 55. Open Source? ‣ Yes! ... but not yet ‣ Relies on unreleased version of Cassandra ‣ ... but the counters patch is committed in trunk (0.8) ‣ ... also relies on some internal frameworks we need to open source
- 56. Open Source? ‣ Yes! ... but not yet ‣ Relies on unreleased version of Cassandra ‣ ... but the counters patch is committed in trunk (0.8) ‣ ... also relies on some internal frameworks we need to open source ‣ It will happen
- 57. Open Source? ‣ Yes! ... but not yet ‣ Relies on unreleased version of Cassandra ‣ ... but the counters patch is committed in trunk (0.8) ‣ ... also relies on some internal frameworks we need to open source ‣ It will happen ‣ See http://github.com/twitter for proof of how much Twitter open source
- 58. Team ‣ John Corwin (@johnxorz) ‣ Adam Samet (@damnitsamet) ‣ Johan Oskarsson (@skr) ‣ Kelvin Kakugawa (@kelvin) ‣ Chris Goffinet (@lenn0x) ‣ Steve Jiang (@sjiang) ‣ Kevin Weil (@kevinweil)
- 59. If You Only Remember One Slide... ‣ Rainbird is a distributed, high-volume counting service built on top of Cassandra ‣ Write 100,000s events per second, query it with hierarchy and multiple time granularities, returns results in <100 ms ‣ Used by Twitter for multiple products internally, including our Promoted Products, operational monitoring and Tweet Button ‣ Will be open sourced so the community can use and improve it!
- 60. Questions? Follow me: @kevinweil TM
Editor's Notes
- #2: \n
- #3: \n
- #4: \n
- #5: \n
- #6: \n
- #7: \n
- #8: \n
- #9: \n
- #10: \n
- #11: \n
- #12: \n
- #13: \n
- #14: \n
- #15: \n
- #16: \n
- #17: \n
- #18: \n
- #19: \n
- #20: \n
- #21: \n
- #22: \n
- #23: \n
- #24: \n
- #25: \n
- #26: \n
- #27: \n
- #28: \n
- #29: \n
- #30: \n
- #31: \n
- #32: \n
- #33: \n
- #34: \n
- #35: \n
- #36: \n
- #37: \n
- #38: \n
- #39: \n
- #40: \n
- #41: \n
- #42: \n
- #43: \n
- #44: \n
- #45: \n
- #46: \n
- #47: \n
- #48: \n
- #49: \n
- #50: \n
- #51: \n
- #52: \n
- #53: \n
- #54: \n
- #55: \n
- #56: \n
- #57: \n
- #58: \n
- #59: \n
- #60: \n
- #61: \n