The link to this page: http://j.mp/ubiquity-workshop-doc.
Table of Contents
- Workshop: Processing And Analyzing Real-time Event Streams in the Cloud
You'll work on your own laptop, and you'll need to do some setup prep before you get started.
The workshop runs for 2 hours, though you can continue working on your own afterwards.
There are many challenges in processing and analyzing data streams from IoT devices.
We typically need to take into account:
- intermittent connectivity -- sometimes devices are offline, receive events later
- late-arriving data - want to analyze based on when the events happened, not when they were received
- large volumes of data, 'unending' streams
- multiple input and output streams
- want to do stream analysis/processing/monitoring in near-realtime, not do 'offline' batch analysis
- handle bursts of activity
- integrate and synchronize multiple event streams
We want a system that:
- ‘keeps up’ with the event stream(s)
- can respond in close to realtime where appropriate
- scales resources up and down with demand
- does once-and-only-once data element processing
- can accommodate late-arriving data
- can detect anomalies in the event stream
This workshop will introduce some Google Cloud Platform (GCP) products and architectural patterns that can help address these IoT needs, with a focus on Cloud Pub/Sub, Cloud Dataflow, and BigQuery.
The workshop includes some presentation of slides introducing concepts, interleaved with hands-on playing and coding. Due to its time constraints, this workshop is really just a 'taster'-- the goal is to get you set up to experiment and play around, and point you to where to get more info.
We'll use a simplified gaming scenario as a running example for the workshop.
- We have a continually running game that many players play, mostly on their mobiles, organized into teams.
- So, we have an 'infinite' event stream of 'plays'.
- There are many different users, who come and go, and are active for various different session intervals.
- Since users play on their mobiles, sometimes they are offline (maybe they're in the subway or on an airplane) and we have late-arriving data.
- We want to analyze the play data with respect to event time, not arrival time.
- We are interested in continual, near-real-time monitoring of the plays.
- E.g., we'd like to monitor scores in an ongoing way, for building a leaderboard, and not have to wait too long to get the scores info.
So, this scenario has many of the IoT domain characteristics listed above.
While this is a 'gaming' domain, the same issues come up in many other IoT device stream processing scenarios too.
The combination of Cloud Pub/Sub, Cloud Dataflow, and BigQuery used together can be a really good fit for these types of IoT scenarios.
We'll switch back to the slides to introduce these services and talk about why they work so well.
(In this workshop, we're focusing primarily on this pattern and set of services-- but there's lots more in the Google Cloud Platform that's relevant to the IoT space too).
We'll start by looking at a Dataflow pipeline from a set of 'gaming' examples that reflect the story above: the LeaderBoard pipeline.
This pipeline does relatively simple analysis, but illustrates a lot of core concepts: it's a 'streaming' pipeline that reads from an unbounded source; it reads from PubSub; it shows how you can use library transforms and build custom transforms; it does streaming writes to BigQuery.
The pipeline calculates running scores information for both individual game players and game teams. We'll take a look at the code after we start up the gaming event stream and the pipeline.
We'll run an Injector program in order to publish lots of simulated game play data to a PubSub topic, so that it can be consumed by a Dataflow pipeline.
The injector is generating lines of game play events that look like this:
user1_RubyCaneToad,RubyCaneToad,16,1450459568000,2015-12-18 09:26:08.351
Each generated line of data has the following form:
username,teamname,score,timestamp_in_ms,readable_time
(This is a very simple game :).
The injector deliberately introduces 'delays' for some of the data. When the injector publishes to PubSub, it adds a timestamp attribute to each PubSub data element. We will instruct Dataflow to interpret this attribute as the event time of a given play. For some of its generated data, the injector will deliberately generate an event time in the past-- this simulates late data (e.g. where the player has been offline for a while).
The injector also generates some deliberate data 'errors', which will cause parse errors in the Dataflow pipeline.
You can imagine a similar scenario where instead of the game play information, many different IoT devices are publishing events and sensor readings to PubSub topic(s).
To run the Injector with a topic called 'gaming', run this maven command from the root of the Dataflow SDK directory, first editing it to use your project name:
$ mvn compile exec:java -pl examples -Dexec.mainClass=com.google.cloud.dataflow.examples.complete.game.injector.Injector -Dexec.args="<your-project> gaming none"You can use any PubSub topic name you like -- the program will create the topic if it doesn't already exist.
If the program exists with a warning about service account credentials, that means you missed a step in your setup.
$ export GOOGLE_APPLICATION_CREDENTIALS=/path/to/your/credentials-key.jsonOnce your injector is running, let's take a look at the PubSub topic info for it in the Developers Console.
You can track some PubSub information under the API Manager in the Developers Console. Expand the list of enabled APIs,and find a link to the PubSub API. Click on that, then Topics.

Alternately, from the Developers Console you can enable the Cloud Monitoring beta (powered by Stackdriver), launch its window, and find PubSub under the Services.


Once the game PubSub injector is running, start up the LeaderBoard Dataflow pipeline, which will consume data from that stream (we'll take a look at its code after we start it up).
When you start up the pipeline, you will need the names of the GCS staging bucket and BigQuery dataset that you defined as per the setup instructions. We'll make the windowing interval for the team scores analysis shorter than the default by passing a command-line argument.
Use this maven command from the root of the Dataflow SDK directory to start up the pipeline. Edit it first with your project name, GCS bucket name, and BigQuery dataset name.
mvn compile exec:java -pl examples -Dexec.mainClass=com.google.cloud.dataflow.examples.complete.game.LeaderBoard -Dexec.args="--project=<your-project> --stagingLocation=gs://<your-staging-bucket> --runner=BlockingDataflowPipelineRunner --dataset=<your-dataset> --topic=projects/<your-project>/topics/gaming --teamWindowDuration=20"Here, we're running the pipeline using the Cloud Dataflow Service, rather than the local runner.
Once the pipeline is up and running, we can take a look at what it's doing in the Dataflow Monitoring UI, which is part of the Developers console. Click on 'Dataflow' in the left nav bar to bring it up. (You can also go directly via:
http://cloud.google.com/console/project/<your-project>/dataflow). This will show you a list of your Dataflow jobs. The one you just started (which may be the only one :) should be at the top of the list. Click on it, and you should see something like this screenshot:

Note that you can inspect sub-steps of the pipeline, get information about amount of data processed and system lag, view logs, etc. Note also that the summary includes a running count of the data parse errors. This is a user-defined counter.
But first let's look at the pipeline code itself.
Let's take a look at the code while the pipeline runs, and break down the pieces of this pipeline.
-
unbounded (streaming) input, use of custom timestamps in support of event time processing
-
Parsing the input data lines into POJOs, and using a user-defined counter for the parse errors
-
The windowing specifications:
fixed windows, with speculative and late result handling of event time data, for team score analysis
global window with periodic results for user score analysis -
Putting it all together: the main() method builds and runs the pipeline.
Once the pipeline has been running for a while, let's take a look at the results in BigQuery.
Go to the BigQuery console: https://bigquery.cloud.google.com.
First let's look at the results of processing the user scores (edit this query for your correct dataset and table name).
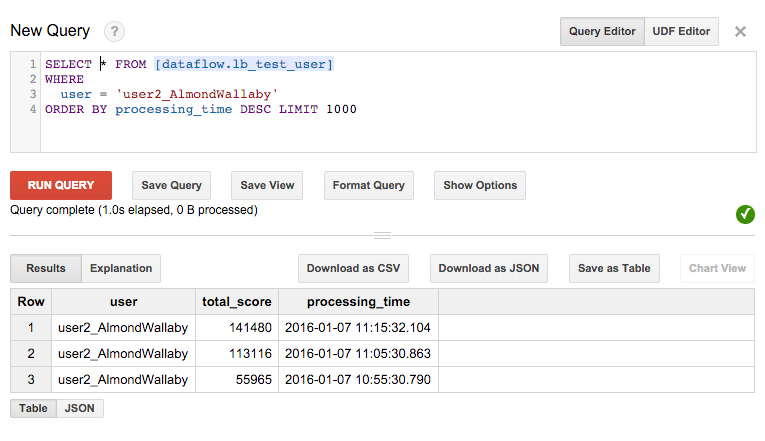
SELECT * FROM [<dataset>.leaderboard_user] order by processing_time desc LIMIT 1000Find a 'user name' from the query above and take a look at data for that user:
SELECT * FROM [<dataset>.leaderboard_user] where user = '<some user name>' order by processing_time desc LIMIT 1000The user score sums are calculated in the context of a global window, from which we're generating periodic updates. Score updates are only generated when there's a change. Since this is an accumulating sum, the change will always be an increase. Since it's a global window, there's no concept of a 'final answer'.
Next, let's look at team score information. With the team scores, we're using fixed windows, and reporting speculative (early) results and late results for each window in addition to the 'on time' score sums. The early results let us monitor how the teams are doing (again, e.g. for a leaderboard).
Our handling of late results lets us update the score sums to include late data if any arrives past the window watermark. Suppose we would like to award team prizes. Our handling of late data is important since we want our scores to be accurate and accommodate delayed data. (You can see in the code that we've set withAllowedLateness in the window definition to 120 minutes by default, but we could set that value to much larger, e.g. 24 hours.)
Because we're calculating sums, and we're using accumulatingFiredPanes in the window definition, the score sums will only increase for a given window.
SELECT * FROM [<dataset>.leaderboard_team] order by processing_time desc LIMIT 1000As we did with the user score info, run the query above to find a team name, then query on that team name to see its info (some teams will be more active than others).
SELECT * FROM [<dataset>.leaderboard_team] where team = '<some team name>'
order by window_start desc, processing_time desc LIMIT 1000You'll only see 'early' updates if there is a change for that period. Similarly, not all teams will have late results to report. Here's an example of results for one team:
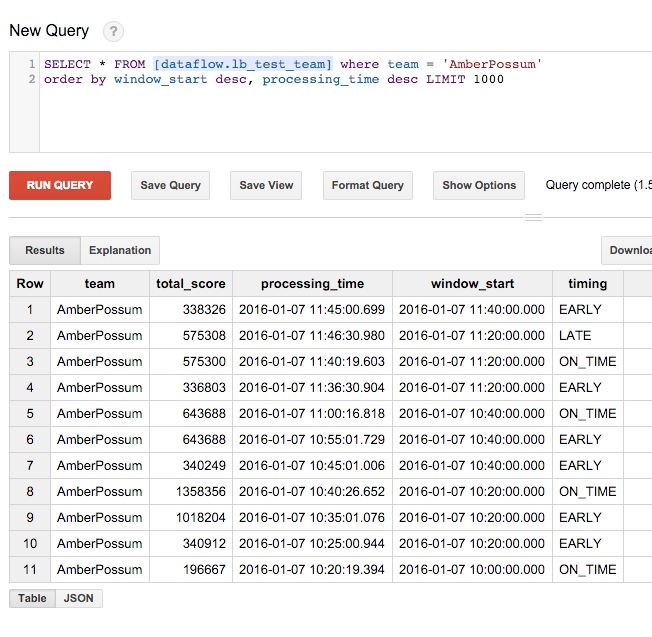
Then, after some time elapses, the team comes online again and makes more plays:

Now let's change the LeaderBoard pipeline to use a new transform.
Copy LeaderBoard.java to create a new class named LeaderBoardCount. We'll modify it to use the Count transform instead of the Sum transform. Count, like Sum, is a pre-provided transform. (You may be interested to read more about the Combine and how it is used in many of these library transforms.)
To make this change, copy the ExtractAndSumScore inner class from UserScore (a superclass of LeaderBoard) and use it as a template to create a new inner class in LeaderBoardCount, ExtractAndCountScore, that looks like this:
public static class ExtractAndCountScore
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Long>>> {
private final String field;
ExtractAndCountScore(String field) {
this.field = field;
}
@Override
public PCollection<KV<String, Long>> apply(
PCollection<GameActionInfo> gameInfo) {
return gameInfo
.apply(MapElements
.via((GameActionInfo gInfo) -> KV.of(gInfo.getKey(field), gInfo.getScore()))
.withOutputType(new TypeDescriptor<KV<String, Integer>>() {}))
.apply(Count.<String, Integer>perKey());
}
}Note the use of Count.
Because this transform returns data elements of type KV<String, Long> (not KV<String, Integer>), we'll also need to modify
the WriteScoresToBigQuery inner class accordingly, so that the types match. We can also change the name of the BigQuery table column while we're at it, from 'total_score' to 'count'.
public static class WriteScoresToBigQuery
extends PTransform<PCollection<KV<String, Long>>, PDone> {
private final String fieldName;
private final String tablePrefix;
private final boolean writeTiming; // Whether to write timing info to the resultant table.
private final boolean writeWindowStart; // whether to include window start info.
public WriteScoresToBigQuery(String tablePrefix, String fieldName,
boolean writeWindowStart, boolean writeTiming) {
this.fieldName = fieldName;
this.tablePrefix = tablePrefix;
this.writeWindowStart = writeWindowStart;
this.writeTiming = writeTiming;
}
/** Convert each key/score pair into a BigQuery TableRow. */
private class BuildFixedRowFn extends DoFn<KV<String, Long>, TableRow>
implements RequiresWindowAccess {
@Override
public void processElement(ProcessContext c) {
// IntervalWindow w = (IntervalWindow) c.window();
TableRow row = new TableRow()
.set(fieldName, c.element().getKey())
.set("count", c.element().getValue().longValue())
.set("processing_time", fmt.print(Instant.now()));
if (writeWindowStart) {
IntervalWindow w = (IntervalWindow) c.window();
row.set("window_start", fmt.print(w.start()));
}
if (writeTiming) {
row.set("timing", c.pane().getTiming().toString());
}
c.output(row);
}
}
/** Build the output table schema. */
private TableSchema getFixedSchema() {
List<TableFieldSchema> fields = new ArrayList<>();
fields.add(new TableFieldSchema().setName(fieldName).setType("STRING"));
fields.add(new TableFieldSchema().setName("count").setType("INTEGER"));
fields.add(new TableFieldSchema().setName("processing_time").setType("STRING"));
if (writeWindowStart) {
fields.add(new TableFieldSchema().setName("window_start").setType("STRING"));
}
if (writeTiming) {
fields.add(new TableFieldSchema().setName("timing").setType("STRING"));
}
return new TableSchema().setFields(fields);
}
@Override
public PDone apply(PCollection<KV<String, Long>> teamAndScore) {
return teamAndScore
.apply(ParDo.named("ConvertToFixedTriggersRow").of(new BuildFixedRowFn()))
.apply(BigQueryIO.Write
.to(getTable(teamAndScore.getPipeline(),
tablePrefix + "_" + fieldName))
.withSchema(getFixedSchema())
.withCreateDisposition(CreateDisposition.CREATE_IF_NEEDED));
}
}Then, delete the 'user processing' branch of the pipeline to make things simpler for this example (else we'd have to do some further editing): https://gist.github.com/amygdala/ecf8f718d23b3514763d#file-leaderboardcount-java-L273
Here's the end result:
- The new ExtractAndCountScore inner class.
- The modification of WriteScoresToBigQuery.
- Removal of the 'user processing' branch of the pipeline.
When you run this new pipeline, explicitly set the tableName input arg to a prefix not yet used in your dataset so that you don't get a conflict:
mvn compile exec:java -pl examples -Dexec.mainClass=com.google.cloud.dataflow.examples.complete.game.LeaderBoard -Dexec.args="--project=<your-project> --stagingLocation=gs://<your-staging-bucket> --runner=BlockingDataflowPipelineRunner --dataset=<your-dataset> --topic=projects/<your-project>/topics/<your-pubsub-topic> --teamWindowDuration=20 --tableName=lb_count"The new table in BigQuery is tracking and accumulating counts of plays instead of sums of scores. Take a look at it like this:
SELECT * FROM [<dataset>.lb_count_team]
order by window_start desc, processing_time desc LIMIT 1000This Dataflow repo holds many other Dataflow examples. The examples directory in the Dataflow SDK repo points to essentially the same set of examples (sometimes it holds new examples not yet in the dedicated examples repo).
This [Mobile Gaming Pipeline](Mobile Gaming Pipeline Examples) tutorial walks through a series of 'gaming' example pipelines that includes the LeaderBoard pipeline used here. There are lots of fun animations that help explain what's going on. In particular, you might be interested in the walkthrough of the GameStats pipeline, a more complex streaming pipeline.
This walkthrough, which works through a series of four successively more detailed WordCount examples that build on each other, is a good starting point if you're just learning about Dataflow.
If you didn't install Java 8, but do have Java 7, most of the Dataflow examples require only Java 7.
This O'Reilly article by Tyler Akidau and related podcast, and then the follow-on, "The world beyond batch: Streaming 102", are a great introduction to Dataflow streaming concepts.
This Stack Overflow tag is a good resource for Dataflow questions: stackoverflow.com/questions/tagged/google-cloud-dataflow.
See these repos for more detail on publishing to and reading from PubSub with Python and Java.
Streaming pipelines run indefinitely, so shut them down when you're no longer using them. Shut down your pipeline(s) by hitting ctl-C, or go to the developers console and cancel it there by clicking on the name of the pipeline in the "Dataflow" panel listing, then clicking "Cancel" in the summary pane.
You can also delete your BigQuery tables once you no longer need them.